Everything About a Robots.txt File
What is a Robots.txt File?
A Robots.txt is a text file in which you can communicate with the crawlers (also referred to as robots, spiders, or bots) that crawl websites in order to index them. In return, these sites are then included in the search results.
The first thing a crawler does, before scanning a website, is look for a Robots.txt file. The file can point the crawler to your sitemap or tell it to not crawl certain subdomains. If you want the search engine crawlers to scan everything (which is most common), creating a Robots.txt file is unnecessary. However, if you do have a Robots.txt, you must make sure that it is formatted correctly. An incorrectly formatted Robots.txt, will prevent you from getting indexed and ranking in the SERPs.
How Does a Crawler Behave when Encountering a Robots.txt File?
If a crawler encounters a Robots.txt and it sees some disallowed URL, it will not crawl them; however, it still might index them. This is because even if robots are not allowed to see the content, they still are able to remember the anchor text and/or the backlinks that point to the disallowed URL on the site. Thus, due to the blocked access to the link, the URL will appear in search engines, however, without snippets.
See the example below:

Extra information
In case your domain has an error 404 (Not Found) or 410 (Gone), the crawler will crawl your website despite the presence of the Robots.txt, because the search engine will assume that the Robots.txt file doesn’t exist.
Other errors, like 500 (Internal Server Error), 403 (Forbidden), timeout or ‘unreachable’ take the instructions of Robots.txt into consideration, however the crawl might be postponed until the file is accessible again.
Why is a Robots.txt important for an SEO strategy?
If a Robots.txt is necessary for your inbound marketing strategy, it could enable your site to be crawled as you desire by the crawlers. On the other hand, If the file is incorrectly formatted, it can lead to your website not being shown in the SERPs .
Where can I find my Robots.txt?
You can see if you have a Robots.txt file with Positionly’s On-Page Optimization tool. You can type in your domain and we will tell you if it’s present.
On the other hand, you should manually be able to find or tell if you have a Robots.txt file at the root of your domain. You can check it by typing in your domain’s name and following it by /robots.txt.
e.g. www.domain.com/robots.txt
If you’re using a CMS (content management system) like WordPress, you might already have a Robots.txt file in place.
Here’s how Google’s instruction for the crawlers looks like:
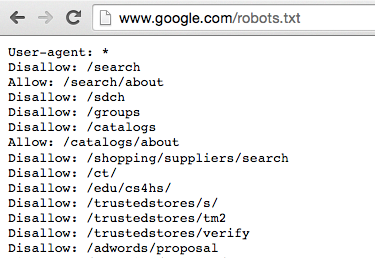
When do you use Robots.txt File?
You should create a Robots.txt file if:
* you have sensitive data or content that you do not want to be crawled
* you do not want for the images on your site to be included in the image search results
* you want to point the crawler easily to your sitemap
* your site is not ready yet and you do not want the robot to index it before it’s fully prepared to be launched
Please bear in mind that the information you want the crawler to avoid is accessible to everyone that enters your URL. Do not use this text file to hide any confidential data.
How Do I Create a Robots.txt File?
The Robots.txt file should be:
* written with lowercase
* using UTF-8 encoding
* saved in a text editor; therefore, it is saved as a text file (.txt)
If you’re doing the file yourself, and you’re not sure where to place it exactly, you can either:
* contact your web server software provider to ask how to access your domain’s root, or
* go to Google Search Console and upload it there
With Google Search Console, you can also test if your Robots.txt was properly done and check which sites were blocked with the use of the file. If you submit the document in Google Search Console, the updated document should be crawled almost immediately.
You can access the Robots.txt Testing Tool here.
An example of a Robots.txt
The basic format of the Robots.txt is the following:

Legend
#
You can add comments, which are only used as notes to keep you organized, by preceding them with an octothorpe (#) tag. These comments will be ignored by the crawlers along with any typos that you happen to make.
User-agent
This tells the crawlers if the instructions are intended for them or not. By adding asterisks (*), you enable any combination of characteristics, so in the example above, you are telling all the crawlers that they can read the data.
e.g.
User-agent: * (the instruction is intended for all search engine crawlers)
User-agent: Googlebot (the instruction is intended only for one specific crawler; here: Googlebot)
Disallow
Tells the crawlers which parts of a website you don’t want to be crawled.
e.g.
- Disallow: / (you disallow crawling of everything)
- Disallow: (you allow the crawler to crawl everything)
- Disallow: /xyz/ (you disallow crawling of a folder /xyz/)
- Disallow: /xyz (you disallow crawling of a folder that starts with the letters ‘xyz’, so it can be /xyz/, /xyzabc/, /xyzabc_photo/ etc)
- Disallow: /.xyz (you disallow crawling folders that start with .xyz)
- Disallow: /*.xyz (you disallow crawling folders that contain .xyz)
- Disallow: /.xyz$ (you disallow crawling folders that end with .xyz)
Allow
Tells the crawlers which parts of the just disallowed content is allowed to be crawled.
e.g.
Allow: /xyz/abc.html (crawler is allowed to crawl one of the files in the folder, here: file /abc/ in folder /xyz/)
Sitemap
Tells all the crawlers where your sitemap’s URL can be found, which speeds the crawling. Adding this is optional.
Please bear in mind that:
- Names of folders are case sensitive, i.e. /xyz/ /XYZ/
- /xyz/ is more specific than /xyz, therefore use the first one whenever possible to be as precise as possible.
A correctly created Robots.txt file is important
A Robots.txt should be used together with a robots meta tag. Remember to use both of them carefully. Otherwise, you might end up with a website that will never appear in the SERPs.